Having some fun with Stable Diffusion Inpainting in Python on New Year's Day

It is New Year’s Day 2023 ![]() . Happy New Year!!!
. Happy New Year!!! ![]() I am currently driving with my family coast-to-coast on a road trip through the United States, but for New Year’s Eve and New Year’s Day we stayed in one place. Taking advantage of the driving free days, I and my 4-year old son had some great fun with the open-source stable diffusion models; in particular, the Text-Guided Image Inpainting techniques.
I am currently driving with my family coast-to-coast on a road trip through the United States, but for New Year’s Eve and New Year’s Day we stayed in one place. Taking advantage of the driving free days, I and my 4-year old son had some great fun with the open-source stable diffusion models; in particular, the Text-Guided Image Inpainting techniques.
Basically, inpainting allows you to replace or transform image areas of your choice with something else AI-generated based on a text prompt. You can see some of my results in the collage above. The top left panel shows the original (real) image. That’s a photo I took of my son during breakfast at a restaurant this morning, and he found it absolutely hilarious how we can drastically modify it with the computer – the text prompts we used were based on his suggestions to a large part.
A few code snippets
I already had played around a few times with image generation with stable diffusion in Python, and with textual inversion for representation of a specific artistic style. Immediately I was (and still am) positively surprised by how easy and pleasant the developers made it to use stable diffusion via the Huggingface diffusers library in Python.
But I haven’t looked at inpainting techniques until today.
I learned a lot from great tutorials about stable diffusion such as the FastAI notebook “Stable Diffusion Deep Dive”, but I haven’t specifically seen examples of inpainting so far (though I haven’t looked ![]() ). So, I’m providing some relevant code snippets here.
). So, I’m providing some relevant code snippets here.
There are two clear ways in which inpainting could be applied to the image I started with (top left in the collage above). Either replace/transform the boy, or replace/transform the drawing that he is holding.
However, first, one has to define an image mask:
- Because I didn’t want to stress about it, I simply guessed by eye rectangular image areas to be masked, for instance as follows (note that I used somewhat different masks for different text prompts):
mask = np.zeros(init_image.size).T
mask[270:, :] = 255
mask[550:, 400:] = 0
mask = Image.fromarray(np.uint8(mask)).convert('RGB')
plt.imshow(mask)
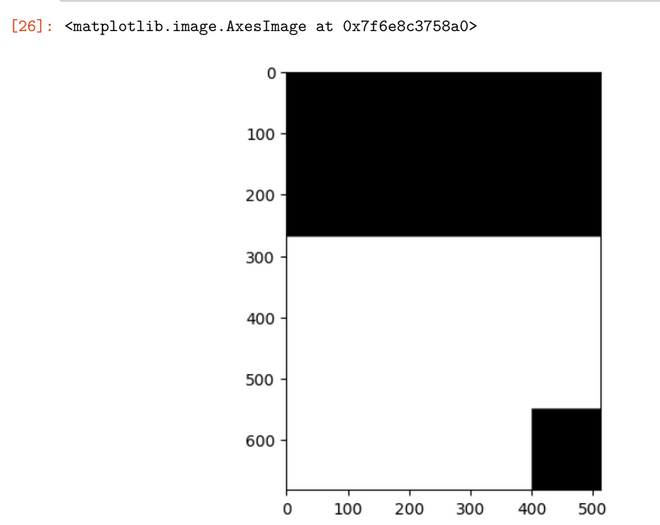
Generating the selected image areas based on a text prompt “from scratch”
- The chosen image areas can be generated from scratch, in which case I used the stable diffusion v2 inpainting model. Here is a corresponding code snippet to download and initiate the pre-trained models and other components of the diffusion pipeline:
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
revision="fp16",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_attention_slicing() # to save some gpu memory in exchange for a small speed decrease
-
Before applying the models, I resized and square-padded all images to 512x512 pixels (I saw the recommendation for square-padding in someone else’s stable diffusion inpainting code, I don’t remember where exactly, and didn’t do any experiments without square-padding).
-
Using the above model, I was able to generate images with code like:
import torch
torch.manual_seed(2023)
inp_img = square_padding(init_image) # my own function, init_image is loaded with PIL.Image
mask = square_padding(mask)
inp_img = inp_img.resize((512, 512))
mask = mask.resize((512, 512))
prompt = "something..."
negative_prompt = "something..."
result = pipe(prompt, image = inp_img, mask_image = mask, negative_prompt=negative_prompt,
num_inference_steps = 50, guidance_scale = 11).images
result[0] # this is the generated image
Generating selected image areas in an image-to-image fashion
Alternatively, the generated image can be created in an image-to-image fashion. For this, I adapted an example from the huggingface/diffusers repository, along the lines of:
from diffusers import DiffusionPipeline
import torch
torch.manual_seed(2023)
inp_img = my_input_image # loaded with PIL.Image
mask = my_image_mask # also PIL.Image
inner_image = inp_img.convert("RGBA")
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
custom_pipeline="img2img_inpainting",
torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing() # to save some gpu memory in exchange for a small speed decrease
prompt = "something..."
negative_prompt = "something..."
result = pipe(prompt=prompt, image=inp_img, inner_image=inner_image,
mask_image=mask, negative_prompt=negative_prompt,
num_inference_steps = 50, guidance_scale = 10).images
result[0] # this is the generated image
Remarks
- Some funny weird behaviors I observed with regards to the prompts:
- When prompted to generate “a newspaper and a cup of vanilla latte on a table in a coffee shop”, the model never actually generated any newspapers in my experiments. Instead, it often imitated text and appearance of a newspaper on the paper cup itself, as you can see in one of the example images shown at the top.
- Instead of “newspaper” I tried to generate “laptop” or “macbook” too, without any success.
- Prompting to generate “paint brushes in front of an oil painting of a flower pot”, in my experiments, either didn’t generate any paint brushes at all, or made a surreal image where the brushes are in and out of the painting at the same time, as you can see in the collage above.
- So, based on my very limited experiments, I’m not sure if stable diffusion can handle terms such as “in front of”, “and”, “or”. I don’t know enough to speculate though (I haven’t even searched the internet about this yet
 ).
).
- When prompted to generate “a newspaper and a cup of vanilla latte on a table in a coffee shop”, the model never actually generated any newspapers in my experiments. Instead, it often imitated text and appearance of a newspaper on the paper cup itself, as you can see in one of the example images shown at the top.
- I used an Nvidia RTX 2080 Ti GPU for the images shown above. I found that particular care must be taken to avoid GPU memory issues, and some things are too finicky for me or impossible without a higher-end GPU. I experimented with some model training (not shown here), but ended up using a more powerful GPU in the cloud after some frustrations.
- Overall this has been a pleasant and fun exercise, and a decent father-son activity with my 4-year old
 (he got a little bored over time but participated throughout suggesting prompts, looking at the results, asking questions). I also like the final results, even though it’s quite obvious that the images have been modified by software.
(he got a little bored over time but participated throughout suggesting prompts, looking at the results, asking questions). I also like the final results, even though it’s quite obvious that the images have been modified by software.